

Autor: Mateus Amorim Marques; MARQUES,M.A.
Mineração de Dados com Azure Machine Learning Studio
Projeto utilizando o DataSet Íris, com o intuito de criar o modelo de classificação, utilizando modelo de classificação em cluster com o algoritmo k-means, separando os dados por classe e observando o desempenho do experimento.
Primeiro utilizamos o modelo de classificação em cluster depois treinamos o modelo utilizando o algoritmo k-means depois criamos um DataSet de exibição com o modelo treinado com as colunas de “class” e “Assignments” exibindo a quantidade classificada de cada um, e por último observando o desempenho do experimento.
Poderíamos utilizar também a plataforma Qlik para visualizar graficamente os resultados da classificação de cada cluster, também poderíamos criar uma Web Services para a solicitação de informação pelo próprio cliente.
Inserindo Iris DataSet no ML Studio:

Inserindo o Iris DataSet no experimento:
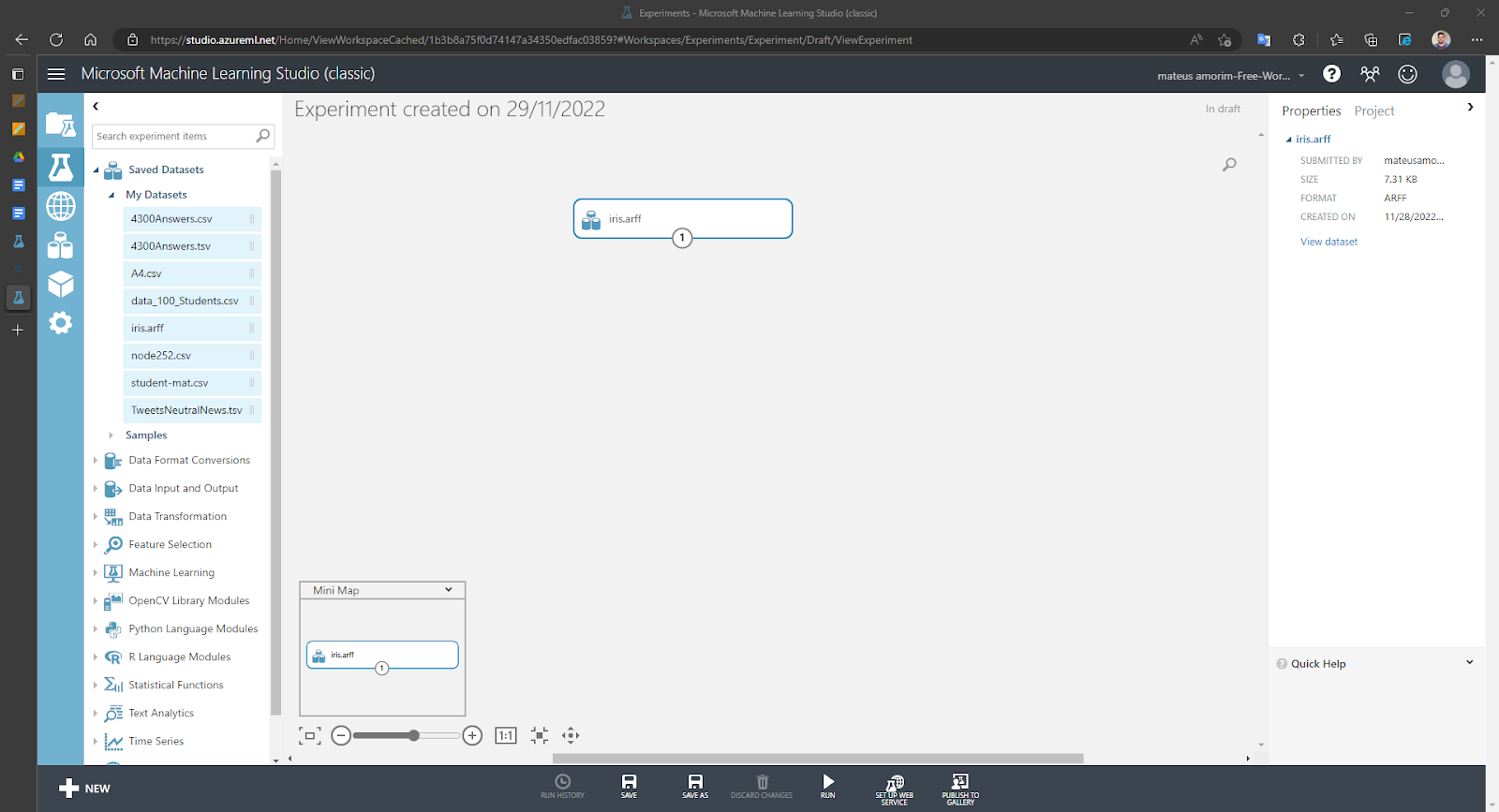
Inserindo o modelo de treinamento em cluster, utilizando todas as colunas:


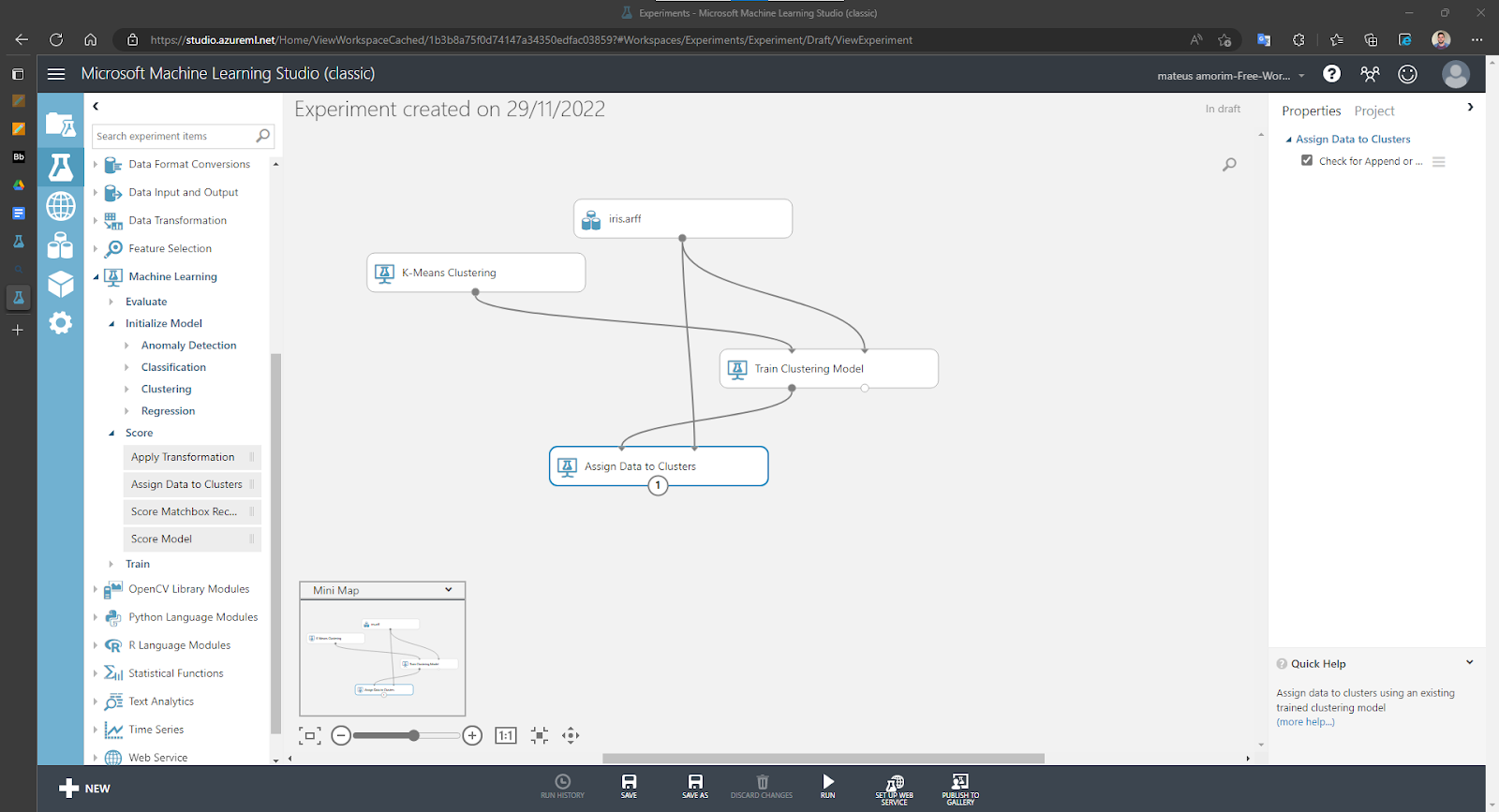
Usando também o algoritmo k-means com o número de centróides igual a 3, com distância euclidiana, e quantidade de iterações igual a 100:

Assinalando as instâncias do cluster:
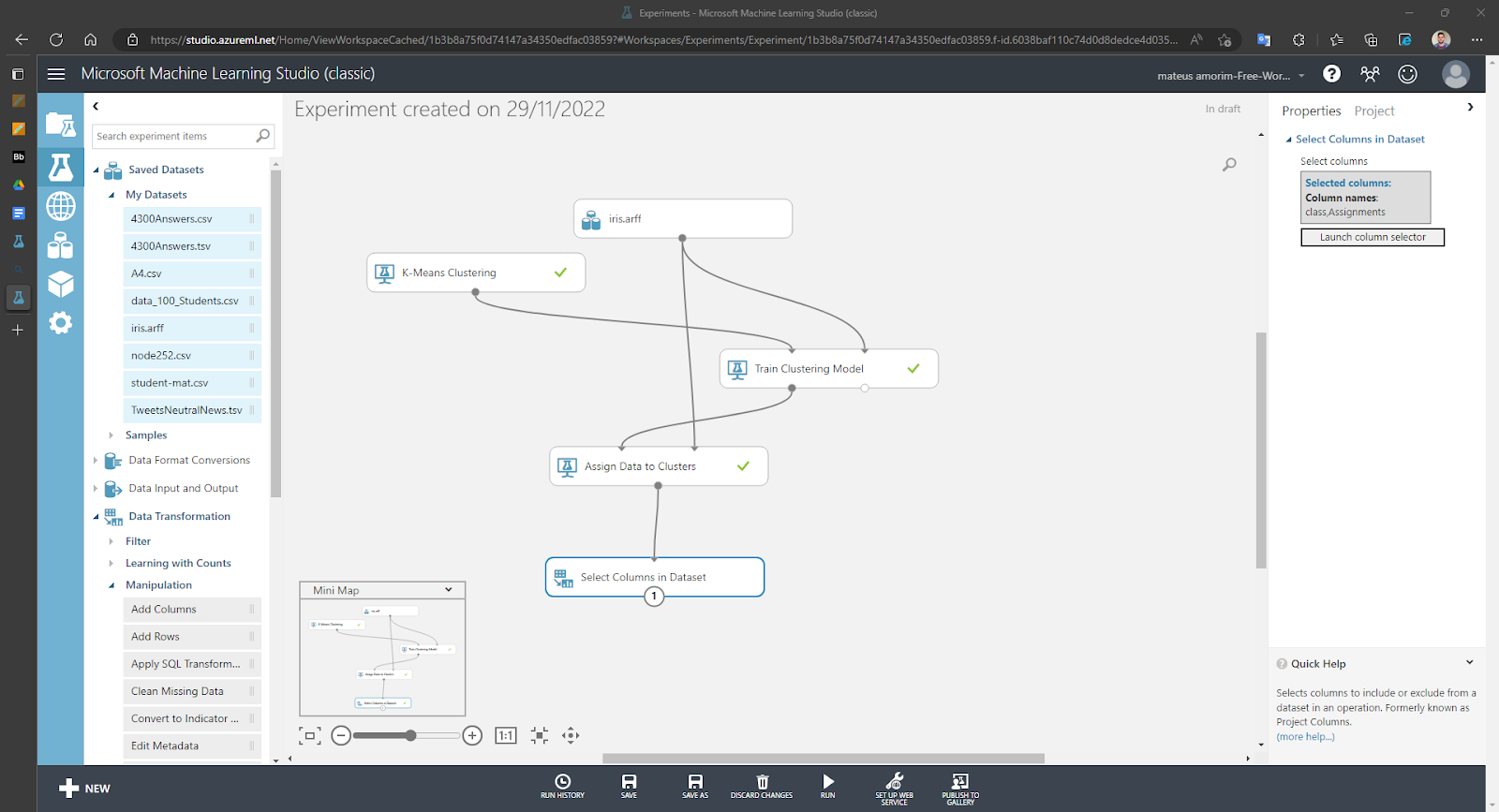
Mostrando o DataSet selecionando as colunas “class” e "Assignments":
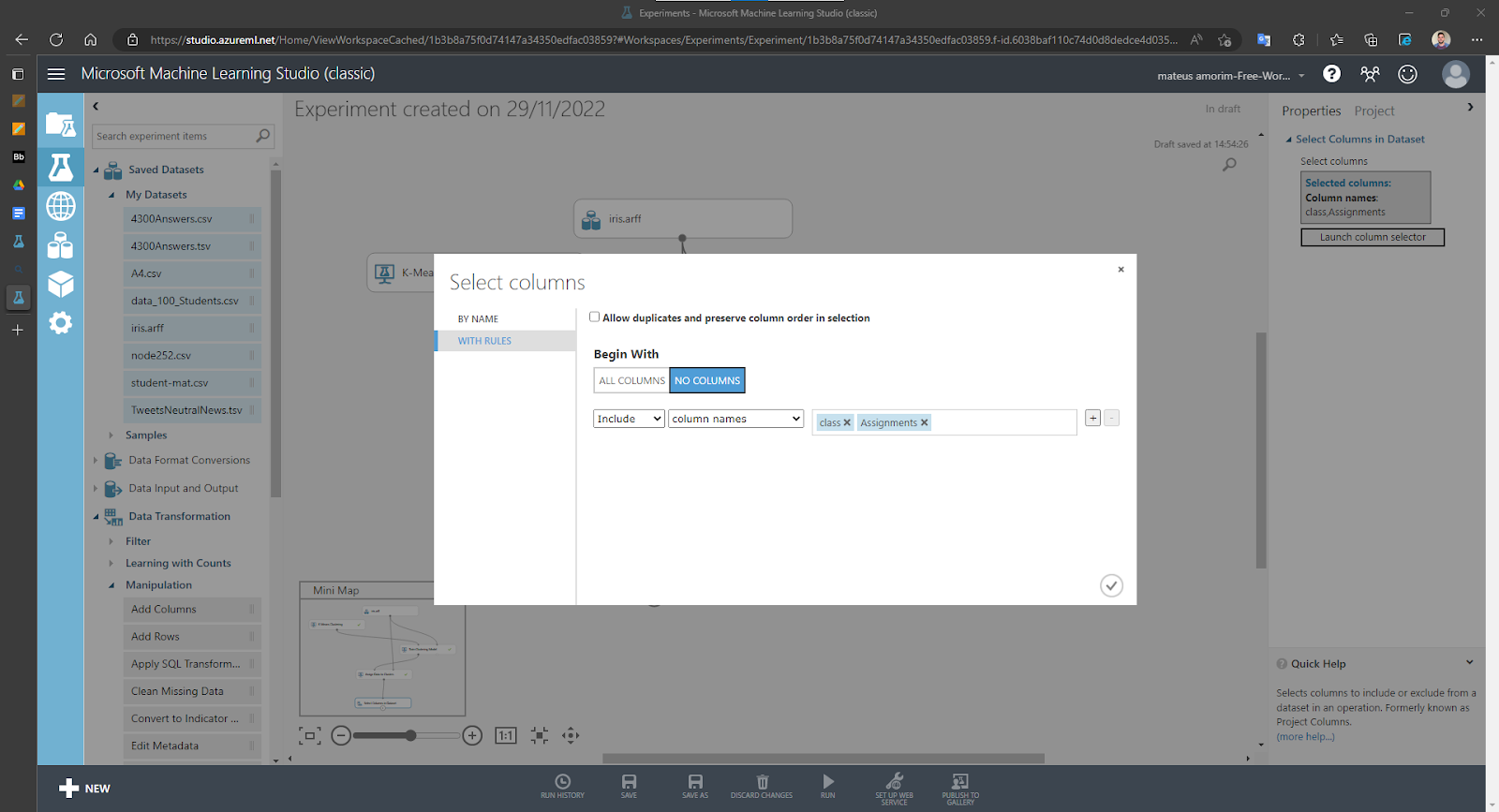
Assinalando as instâncias dos clusters e observando o resultado:
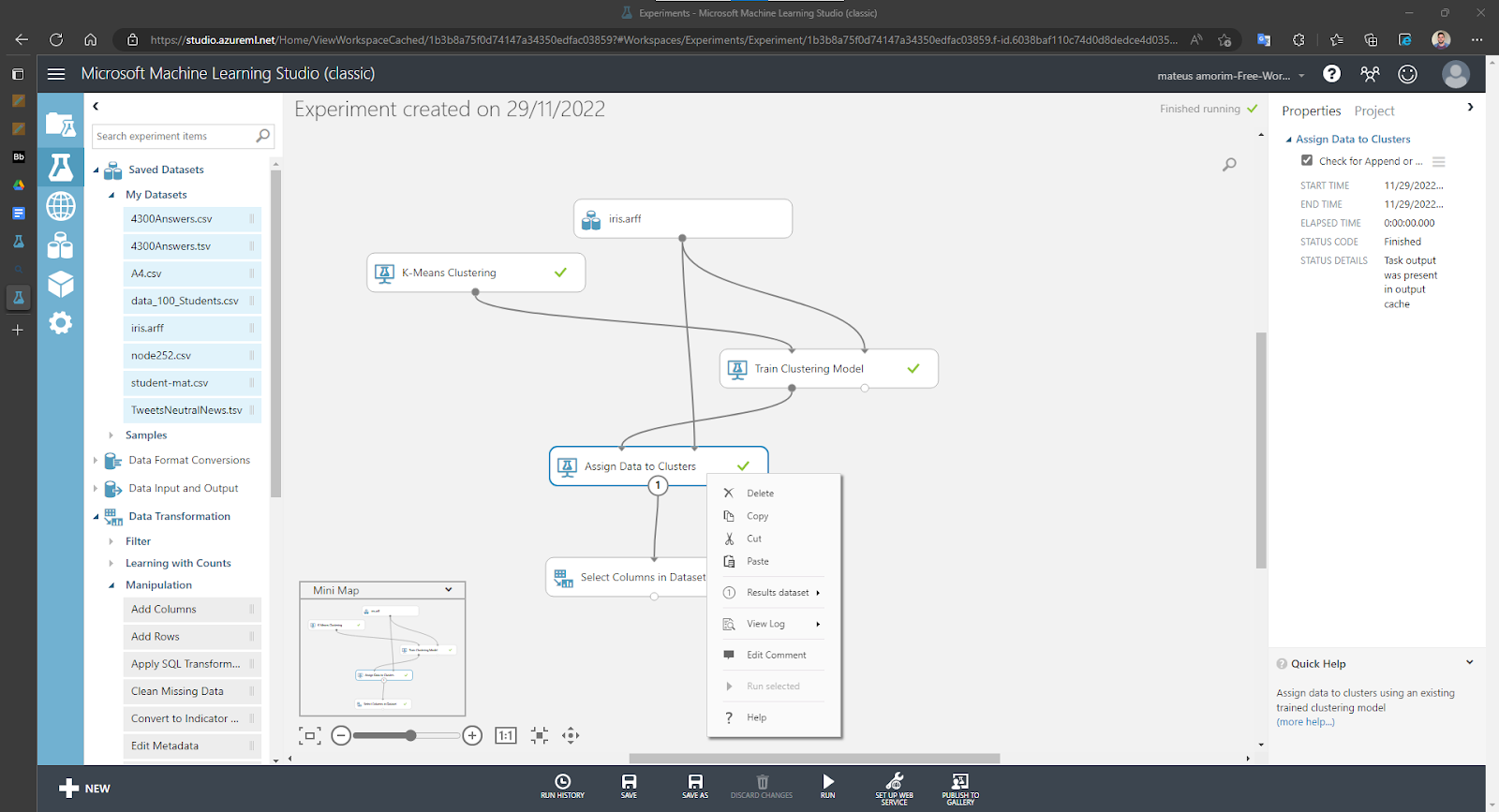

Exibindo o resultado do experimento, visualizando os clusters gerados:
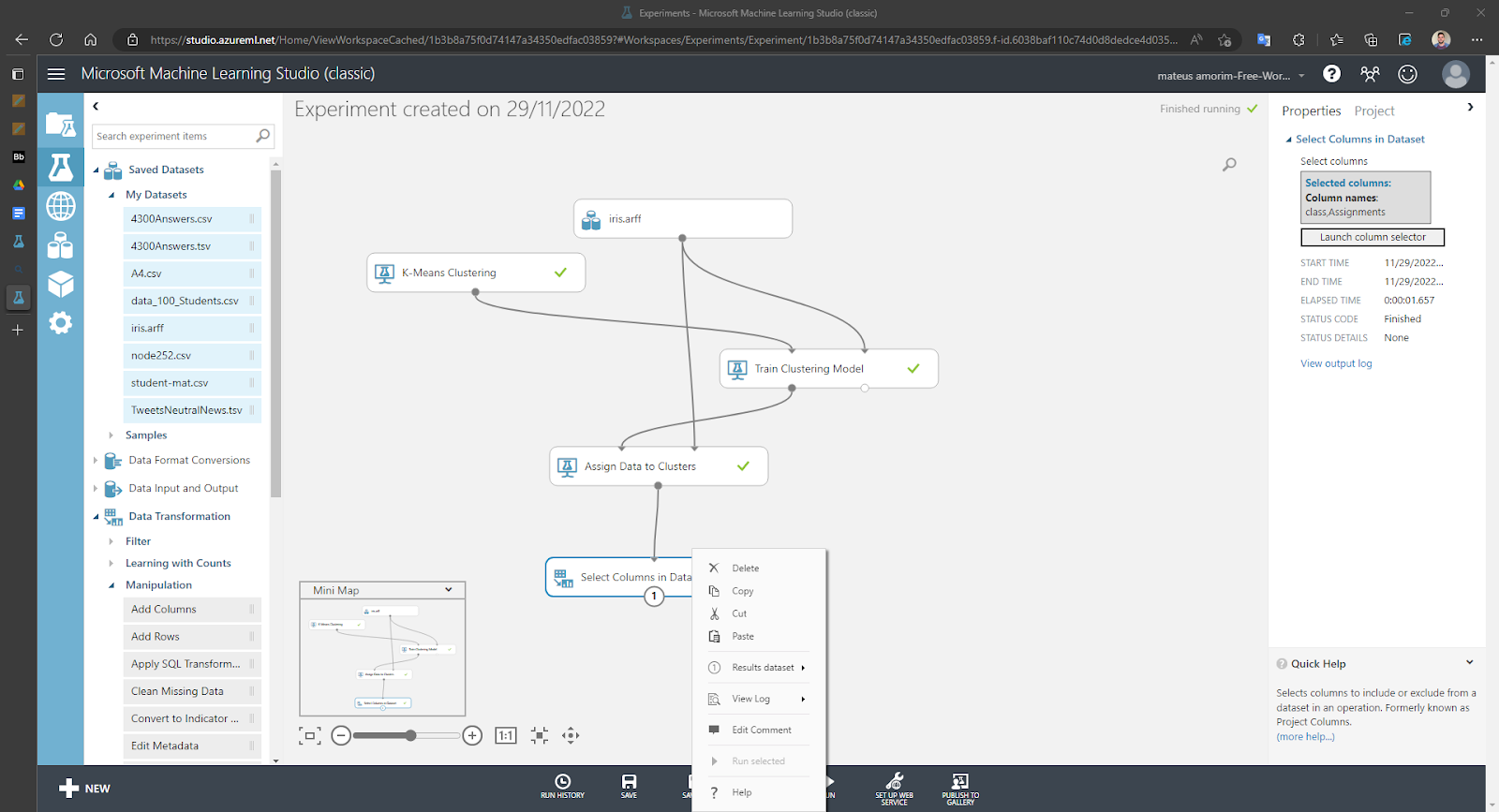


O “Iris-setosa” está representado pelo “0”
O “Iris-versicolor” pelo “2”
E o “Iris-Virginica” pelo “1”
Podemos observar que o modelo treinado é muito bom, apenas uma instância foi classificada de forma incorreta.
Podemos observar ainda que o maior cluster classificado é o “Iris-versicolor”, depois o “Iris-Virginica”, por último o “Iris-setosa”.
Comentários
Postar um comentário